Микропроцессоры нетрадиционных архитектур
6.1. Ассоциативные процессоры
Существующие в настоящее время алгоритмы прикладных задач, системное программное обеспечение и аппаратные средства преимущественно ориентированы на традиционную адресную об-работку данных. Данные должны быть представлены в виде огра-ниченного количества форматов (например, массивы, списки, за-писи), должна быть явно создана структура связей между элемен-тами данных посредством указателей на адреса элементов памяти, при обработке этих данных должна быть выполнена совокупность операций, обеспечивающих доступ к данным по указателям. Такой подход обуславливает громоздкость операционных систем и сис-тем программирования, а также служит препятствием к созданию вычислительных средств с архитектурой, ориентированной на бо-лее эффективное использование параллелизма обработки данных.
Ассоциативный способ обработки данных позволяет пре-одолеть многие ограничения, присущие адресному доступу к па-мяти, за счет задания некоторого критерия отбора и проведение требуемых преобразований, только над теми данными, которые удовлетворяют этому критерию. Критерием отбора может быть совпадение с любым элементом данных, достаточным для выделе-ния искомых данных из всех данных. Поиск данных может проис-ходить по фрагменту, имеющему большую или меньшую корреля-цию с заданным элементом данных.
Исследованы и в разной степени используются несколько подходов, различающихся полнотой реализации модели ассоциа-тивной обработки. Если реализуется только ассоциативная выбор-ка данных с последующим поочередным использованием найден-ных данных, то говорят об ассоциативной памяти или памяти, ад-ресуемой по содержимому. При достаточно полной реализации всех свойств ассоциативной обработки, используется термин «ас-социативный процессор».
Ассоциативные системы относятся к классу: один поток команд - множество потоков данных (SIMD = Single Instruction Multiple Data). Эти системы включают большое число операционных устройств, способных одновременно по командам управ-ляющего устройства вести обработку нескольких потоков данных. В ассоциативных вычислительных системах информация на обра-ботку поступает от ассоциативных запоминающих устройств (АЗУ), характеризующиеся тем, что информация в них выбирается не по определенному адресу, а по ее содержанию.
6.2. Матричные процессоры
Наиболее распространенными из систем, класса: один поток команд - множество - потоков данных (SIMD), являются матрич-ные системы, которые лучше всего приспособлены для решения задач, характеризующихся параллелизмом независимых объектов или данных. Организация систем подобного типа на первый взгляд достаточно проста. Они имеют общее управляющее устройство, генерирующее поток команд и большое число процессорных эле-ментов, работающих параллельно и обрабатывающих каждая свой поток данных.
Таким образом, производительность системы оказывается равной сумме производительностей всех процессорных элементов. Однако на практике, чтобы обеспечить достаточную эффектив-ность системы при решении широкого круга задач необходимо ор-ганизовать связи между процессорными элементами с тем, чтобы наиболее полно загрузить их работой. Именно характер связей между процессорными элементами и определяет разные свойства системы.
Одним из первых матричных процессоров был SОLОМОN (60-е годы) (рис. 1). Система SОLOМОN содержит 1024 процес-сорных элемента, соединены в виде матрицы: 32х32. Каждый про-цессорный элемент матрицы включает в себя процессор, обеспе-чивающий выполнение последовательных поразрядных арифмети-ческих и логических операций, а также оперативное ЗУ, емкостью 16 Кбайт. Длина слова - переменная от 1 до 128 разрядов. Разряд-ность слов устанавливается программно. По каналам связи от уст-ройства управления передаются команды и общие константы.

Рис. 1
В процессорном элементе используется, так называемая, многомодальная логика, которая позволяет каждому процессорно-му элементу выполнять или не выполнять общую операцию в за-висимости от значений обрабатываемых данных. В каждый мо-мент все активные процессорные элементы выполняют одну и ту же операцию над данными, хранящимися в собственной памяти и имеющими один и тот же адрес.
Идея многомодальности заключается в том, что в каждом процессорном элементе имеется специальный регистр на 4 состоя-ния - регистр моды. Мода (модальность) заносится в этот регистр от устройства управления. При выполнении последовательности команд модальность передается в коде операции и сравнивается с содержимым регистра моды. Если есть совпадения, то операция выполняется. В других случаях процессорный элемент не выпол-няет операцию, но может, в зависимости от кода, пересылать свои операнды соседнему процессорному элементу. Такой механизм позволяет выделить строку или столбец процессорных элементов, что очень полезно при операциях над матрицами. Взаимодейству-ют процессорные элементы с периферийным оборудованием через внешний процессор.
кулами.
Дальнейшим развитием матричных процессоров стала система ILLIАS-4, разработанная фирмой Barroys. Первоначально система должна была включать в себя 256 процессорных элемен-тов, разбитых на группы, каждый из которых должен управляться специальным процессором. Однако по различным причинам была создана система, содержащая одну группу процессорных элемен-тов и управляющий процессор. Если в начале предполагалось дос-тичь быстродействия порядка 1 млрд. операций в секунду, то ре-альная система работала с быстродействием около 200 млн. опера-ций в секунду. Эта система в течение ряда лет считалась одной из самых высокопроизводительных в мире.
6.3. ДНК процессоры
В настоящее время в поисках реальной альтернативы полу-проводниковым технологиям создания новых вычислительных систем ученые обращают все большее внимание на биотехноло-гии, или биокомпьютинг, который представляет собой гибрид ин-формационных, молекулярных технологий, также биохимии. Био-компьютинг позволяет решать сложные вычислительные задачи, пользуясь методами, принятыми в биохимии и молекулярной био-логии, организуя вычисления при помощи живых тканей, клеток, вирусов и биомолекул.
Наибольшее распространение получил подход, где в каче-стве основного элемента (процессора) используются молекулы де-зоксирибонуклеиновой кислоты. Центральное место в этом подхо-де занимает так называемый ДНК - процессор. Кроме ДНК в каче-стве био-процессора могут быть использованы также белковые молекулы и биологические мембраны.
Так же, как и любой другой процес-сор, ДНК процессор характеризуется структурой и набором команд. В нашем случае структура процессора - это структу-ра молекулы ДНК. А набор команд - это перечень биохимических операций с моле
Принцип устройства компьютерной ДНК-памяти осно-ван на последовательном соединении четырех нуклеотидов (ос-новных кирпичиков ДНК-цепи). Три нуклеотида, соединяясь в любой последовательности, образуют элементарную ячейку памя-ти - кодон, которые затем формируют цепь ДНК. Основная труд-ность в разработке ДНК-компьютеров связана с проведением из-бирательных однокодонных реакций (взаимодействий) внутри це-пи ДНК. Однако прогресс есть уже и в этом направлении. Уже есть экспериментальное оборудование, позволяющее работать с одним из 1020 кодонов или молекул ДНК. Другой проблемой яв-ляется самосборка ДНК, приводящая к потере информации. Ее преодолевают введением в клетку специальных ингибиторов - ве-ществ, предотвращающих химическую реакцию самосшивки.
Использование молекул DNA для организации вычислений – это не слишком новая идея. Теоретическое обоснование подоб-ной возможности было сделано еще в 50-х годах прошлого века (Р.П. Фейманом). В деталях эта теория была проработана в 70-х годах Ч. Бенеттом и в 80-х М. Конрадом.
Первый компьютер на базе ДНК был создан еще в 1994 г. американским ученым Леонардом Адлеманом. Он смешал в про-бирке молекулу ДНК, в которой были закодированы исходные данные, и специальным образом подобранные ферменты. В ре-зультате химической реакции структура ДНК изменилась таким образом, что в ней в закодированном виде был представлен ответ задачи. Поскольку вычисления проводились в ходе химической реакции с участием ферментов, на них было затрачено очень мало времени.
Ричард Липтон из Принстона первым показал, как, исполь-зуя ДНК, кодировать двоичные числа и решать проблему удовле-творения логического выражения. Суть ее в том, что, имея некото-рое логическое выражение, включающее n логических перемен-ных, нужно найти все комбинации значений переменных, делаю-щих выражение истинным. Задачу можно решить только перебо-ром 2n комбинаций. Все эти комбинации легко закодировать с по-мощью ДНК, а дальше действовать по методике Адлемана.
Первую модель биокомпьютера, правда, в виде механизма из пластмассы, в 1999 г. создал Ихуд Шапиро из Вейцмановского
института естественных наук. Она имитировала работу “моле-кулярной машины” в живой клетке, собирающей белковые моле-кулы по информации с ДНК, используя РНК в качестве посредни-ка между ДНК и белком.
А в 2001 г. Шапиро удалось реализовать вычислительное устройство на основе ДНК, которое может работать почти без вмешательства человека. Система имитирует машину Тьюринга — одну из фундаментальных концепций вычислительной техники. Машина Тьюринга шаг за шагом считывает данные и в зависимо-сти от их значений принимает решения о дальнейших действиях. Теоретически она может решить любую вычислительную задачу. По своей природе молекулы ДНК работают аналогичным образом, распадаясь и рекомбинируя в соответствии с информацией, зако-дированной в цепочках химических соединений.
Разработанная в Вейцмановском институте установка коди-рует входные данные и программы в состоящих из двух цепей мо-лекулах ДНК и смешивает их с двумя ферментами. Молекулы фермента выполняли роль аппаратного, а молекулы ДНК - про-граммного обеспечения. Один фермент расщепляет молекулу ДНК с входными данными на отрезки разной длины в зависимости от содержащегося в ней кода. А другой рекомбинирует эти отрезки в соответствии с их кодом и кодом молекулы ДНК с программой. Процесс продолжается вдоль входной цепи, и, когда доходит до конца, получается выходная молекула, соответствующая конечно-му состоянию системы.
Этот механизм может использоваться для решения самых разных задач. Хотя на уровне отдельных молекул обработка ДНК происходит медленно - с типичной скоростью от 500 до 1000 бит/с, что во много миллионов раз медленнее современных крем-ниевых процессоров, по своей природе она допускает массовый параллелизм. По оценкам Шапиро и его коллег, в одной пробирке может одновременно происходить триллион процессов, так что при потребляемой мощности в единицы нановатт может выпол-няться миллиард операций в секунду.
В 2002 г. фирма Olympus Optical разработала версию ДНК-компьютера, предназначенного для генетического анализа. Он имеет молекулярную и электронную составляющие. Первая осу
Для этой цели идеально подош
п д
ществляет химические реакции между молекулами ДНК, обес-печивает поиск и выделение результата вычислений. Вторая - об-рабатывает информацию и анализирует полученные результаты.
Возможностями биокомпьютеров заинтересовались и воен-ные. Американское агентство по исследованиям в области оборо-ны DARPA выполняет проект, получивший название Bio-Comp (Biological Computations, биологические вычисления). Его цель - создание мощных вычислительных систем на основе ДНК.
Пока до практического применения компьютеров на базе ДНК еще очень далеко. Однако в будущем их смогут использовать не только для вычислений, но и как своеобразные нанофабрики лекарств. Поместив подобное "устройство" в клетку, врачи смогут влиять на ее состояние, исцеляя человека от самых опасных недугов.
6.4. Клеточные процессоры
Клеточные процессоры представляют собойсамооргани-зующиеся колонии различных "умных" микроорганизмов, в геном которых удалось включить некую логическую схему, которая мог-ла бы активизироваться в присутствии определенного вещества. ли бы бактерии, стакан с которыми и представлял бы собой компью-тер. Такие компьютеры очень де-шевы в производстве. Им не нужна столь стерильная атмосфера, как при производстве полуровони-ков.
Главным свойством процес-сора такого рода является то, что каждая их клетка представляет со-бой миниатюрную химическую ла-бораторию. Если биоорганизм за-программирован, то он просто производит нужные вещества. Дос-таточно вырастить одну клетку, обладающую заданными качест-вами, и можно легко и быстро вырастить тысячи клеток с такой же программой.
Основная проблема, с которой сталкиваются создатели клеточных биокомпьютеров, - организация всех клеток в единую работающую систему. На сегодняшний день практические дости-жения в области клеточных компьютеров напоминают достижения 20-х годов в области ламповых и полупроводниковых компьюте-ров. В Лаборатории искусственного интеллекта Массачусетского технологического университета создана клетка, способная хранить на генетическом уровне 1 бит информации. Также разрабатывают-ся технологии, позволяющие единичной бактерии отыскивать сво-их соседей, образовывать с ними упорядоченную структуру и осуществлять массив параллельных операций.
В 2001 г. американские ученые создали трансгенные мик-роорганизмы (т. е. микроорганизмы с искусственно измененными генами), клетки которых могут выполнять логические операции И и ИЛИ.
Специалисты лаборатории Оук-Ридж, штат Теннесси, ис-пользовали способность генов синтезировать тот или иной белок под воздействием определенной группы химических раздражите-лей. Ученые изменили генетический код бактерий Pseudomonas putida таким образом, что их клетки обрели способность выпол-нять простые логические операции. Например, при выполнении операции И в клетку подаются два вещества (по сути - входные операнды), под влиянием которых ген вырабатывает определен-ный белок. Теперь учеными ведутся работы по созданию на базе этих клеток более сложных логических элементов, а также работы по созданию клетки, выполняющей параллельно несколько логи-ческих операций.
Потенциал биокомпьютеров очень велик. К достоинствам, выгодно отличающим их от компьютеров, основанных на крем-ниевых технологиях, относятся:
1) более простая технология изготовления, не требующая для своей реализации столь жестких условий, как при производст-ве полупроводников
2) использование не бинарного, а тернарного кода (инфор-мация кодируется тройками нуклеотидов), что позволит при меньшем количестве шагов перебрать большее число вариантов при анализе сложных систем
3) потенциально исключительно высокая производи-тельность, которая может составлять до 1014 операций в секунду за счет одновременного вступления в реакцию триллионов моле-кул ДНК
4) возможность хранить данные с плотностью, в триллионы раз превышающей показатели оптических дисков
5) исключительно низкое энергопотребление
Однако, наряду с очевидными достоинствами, биокомпью-теры имеют и существенные недостатки, такие как:
1) сложность со считыванием результатов - современные способы определения кодирующей последовательности не совер-шенны, сложны, трудоемки и дороги
2) низкая точность вычислений, связанная с возникновени-ем мутаций, прилипанием молекул к стенкам сосудов и т.д.
3) невозможность длительного хранения результатов вы-числений в связи с распадом ДНК в течение времени
Хотя до практического использования биокомпьютеров еще очень далеко, но предполагается, что, они найдут достойное при-менение в медицине и фармакологии, а также с их помощью ста-нет возможным объединение информационных и биотехнологий.
6.5. Коммуникационные процессоры
Коммуникационные процессоры - это микрочипы, являю-щие собой нечто среднее между жесткими специализированными интегральными микросхемами и гибкими процессорами общего назначения.
Коммуникационные процессоры программируются, как и обычные процессоры, но построены с учетом сетевых задач, опти-мизированы для сетевой работы, и на их основе производители - как процессоров, так и оборудования - пишут программное обес-печение для специфических приложений.
Коммуникационный процессор имеет собственную память и оснащен высокоскоростными внешними каналами для соедине-ния с другими процессорными узлами. Его присутствие позволяет в значительной мере освободить вычислительный процессор от нагрузки, связанной с передачей сообщений между процессорны-
158
ми узлами. Скоростной коммуникационный процессор с RISC-ядром позволяет управлять обменом данными по нескольким не-зависимым каналам, поддерживать практически все распростра-ненные протоколы обмена, гибко и эффективно распределять и обрабатывать последовательные потоки данных с временным раз-делением каналов.
Сама идея создания процессоров, предназначенных для оп-тимизации сетевой работы - и при этом достаточно универсальных для программной модификации – родилась в связи с необходимо-стью устранить различия в подходах к созданию локальных сетей (различные подходы к архитектуре сети, классификации потоков, и т.д
Новая серия коммуникационных процессоров Intel IXP4xx построена на базе распределенной архитектуры XScale и включает мощные мультимедийные возможности, а также развитые сетевые интерфейсы Ethernet. Сочетание высокой производительности и низкого энергопотребления позволяет эффективно применять коммуникационные процессоры Intel не только в классических се-тевых приложениях, но и для построения интернет-ориентированных встраиваемых систем промышленного назначе-ния.
Эффективность работы промышленных предприятий сего-дня напрямую зависит от гибкости применяемых систем автомати-зированного управления. Крупные производственные установки требуют использования нескольких децентрализованных систем управления, связанных друг с другом мощной информационной сетью, способной работать в сложных промышленных условиях. Зачастую эти средства промышленной коммуникации призваны обеспечить возможность гибкого управления, программирования и контроля работы распределенных систем управления из удален-ных диспетчерских пунктов. Осуществление этих целей возможно с помощью коммуникационных процессоров, предназначенных для подключения персональных компьютеров к промышленным информационным сетям.
Дополнительные возможности, обеспечиваемые коммуни-кационными процессорами должны быть интересны, прежде всего, тем пользователям, которым необходимо осуществлять сложные
159
транзакции или наладить прямую голосовую и видео передачи в рамках сетевой инфраструктуры.
7.6. Процессоры баз данных
Процессорами (машинами) баз данных в настоящее время принято называть программно- аппаратные комплексы, предна-значенные для выполнения всех или некоторых функций систем управления базами данных (СУБД). Если в свое время системы управления базами данных предназначались в основном для хра-нения текстовой и числовой информации, то теперь они рассчита-ны на самые различные форматы данных, в том числе графиче-ские, звуковые и видео. Процессоры баз данных выполняют функ-ции управления и распространения, обеспечивают дистанционный доступ к информации через шлюзы, а также репликацию обнов-ленных данных с помощью различных механизмов тиражирова-ния.
Современные процессоры баз данных должны обеспечивать естественную связь накапливаемой в базах данных информации со средствами оперативной обработки транзакций и Internet-приложениями. Это должны быть системы, которые дают пользо-вателям возможность в любой момент обратиться к корпоратив-ным данным и проанализировать их, вне зависимости от того, где эти данные размещаются.
Решение таких задач требует существенного увеличения производительности таких систем. Однако традиционная про-граммная реализация многочисленных функций современных СУБД на ЭВМ общего назначения приводит к громоздким и не-производительным системам с недостаточно высокой надежно-стью. Необходим поиск новых архитектурных и аппаратных ре-шений. Интенсивные исследования, проводимые в этой области в настоящее время, привели к пониманию необходимости использо-вания в качестве процессоров баз данных специализированных па-раллельных вычислительных систем. Создание такого рода систем связывается с реализацией параллелизма при выполнении после-довательности операций и транзакций, а также конвейерной пото-ковой обработки данных.
160
7.7. Потоковые процессоры
Потоковыми называют процессора, в основе работы кото-рых лежит принцип обработки многих данных с помощью одной команды. Согласно классификации Флинна они принадлежат к SIMD архитектуре. Технология SIMD позволяет выполнять одно и то же действие, например вычитание и сложение, над несколькими наборами чисел одновременно. SIMD-операции для чисел двойной точности с плавающей запятой ускоряют работу ресурсоемких приложений для создания контента, трехмерного рендеринга, фи-нансовых расчетов и научных задач. Кроме того, усовершенство-ваны возможности 64-разрядной технологии MMX (целочислен-ных SIMD-команд); эта технология распространена на 128-разрядные числа, что позволяет ускорить обработку видео, речи, шифрование, обработку изображений и фотографий. Потоковый процессор повышает общую производительность, что особенно важно при работе с 3D-графическими объектами.
Может быть отдельный потоковый процессор (Single-streaming processor — SSP) и многопотоковый процессор (Multi-Streaming Processor - MSP).
Ярким представителем потоковых процессоров является семейство процессоров Intel, начиная с Pentium III, в основе рабо-ты которых лежит технология Streaming SIMD Extensions (SSE, потоковая обработка по принципу "одна команда - много дан-ных"). Эта технология позволяет выполнять такие сложные и не-обходимые в век Internet задачи, как обработка речи, кодирование и декодирование видео- и аудиоданных, разработка трехмерной графики и обработка изображений.
Бесспорными представителями класса SIMD считаются матрицы процессоров: ILLIAC IV, ICL DAP, Goodyear Aerospace MPP, Connection Machine 1 и т.п. В таких системах единое управ-ляющее устройство контролирует множество процессорных эле-ментов. Каждый процессорный элемент получает от устройства управления в каждый фиксированный момент времени одинако-вую команду и выполняет ее над своими локальными данными.
Другими представителями SIMD-класса являются вектор-ные процессоры, в основе которых лежит векторная обработка
данных. Векторная обработка увеличивает производительность процессора за счет того, что обработка целого набора данных (век-тора) производится одной командой. Векторные компьютеры ма-нипулируют массивами сходных данных подобно тому, как ска-лярные машины обрабатывают отдельные элементы таких масси-вов. В этом случае каждый элемент вектора надо рассматривать как отдельный элемент потока данных. При работе в векторном режиме векторные процессоры обрабатывают данные практически параллельно, что делает их в несколько раз более быстрыми, чем при работе в скалярном режиме. Максимальная скорость передача данных в векторном формате может составлять 64 Гб/с, что на 2 порядка быстрее, чем в скалярных машинах. Примерами систем подобного типа является, например, процессоры фирм NEC и Hitachi.
6.8. Процессоры с многозначной (нечеткой) логикой
Идея построения процессоров с нечеткой логикой (fuzzy logic) основывается на нечеткой математике. Математическая тео-рия нечетких множеств, предложенная проф. Л.А. Заде, являясь предметом интенсивных исследований, открывает все большие возможности перед системными аналитиками. Основанные на этой теории различные компьютерные системы, в свою очередь, суще-ственно расширяют область применения нечеткой логики.
Подходы нечёткой математики дают возможность опериро-вать входными данными, непрерывно меняющимися во времени и значениями, которые невозможно задать однозначно, такими, на-пример, как результаты статистических опросов. В отличие от традиционной формальной логики, известной со времен Аристоте-ля и оперирующей точными и четкими понятиями типа истина и ложь, да и нет, ноль и единица, нечеткая логика имеет дело со зна-чениями, лежащими в некотором (непрерывном или дискретном) диапазоне.
Функция принадлежности элементов к заданному множест-ву также представляет собой не жесткий порог "принадлежит - не принадлежит", а плавную сигмоиду, проходящую все значения от нуля до единицы. Теория нечеткой логики позволяет выполнять
над такими величинами весь спектр логических операций - объ-единение, пересечение, отрицание и др.
Согласно знаменитой теореме FAT (Fuzzy Approximation Theorem), доказанной Коско, любая математическая система мо-жет быть аппроксимирована системой, основанной на нечеткой логике. Свое второе рождение теория нечеткой логики пережила в начале восьмидесятых годов, когда сразу несколько групп иссле-дователей (в основном в США и Японии) всерьез занялись созда-нием электронных систем различного применения, использующих нечеткие управляющие алгоритмы. Используя преимущества не-четкой логики, заключающиеся в простоте содержательного пред-ставления, можно упростить проблему, представить ее в более доступном виде и повысить производительность системы.
Задачи с помощью нечёткой логики решаются по следую-щему принципу:
1) численные данные (показания измерительных приборов, результаты анкетирования) фаззируются (переводятся в нечеткий формат);
2) обрабатываются по определённым правилам;
3) дефаззируются и в виде привычной информации подают-ся на выход.
Оказалось возможным создание нечеткого процессора, по-зволяющего выполнять различные нечеткие операции и прибли-женные рассуждения (нечеткий вывод) в соответствии с правила-ми логического вывода. В 1986 году в AT&T Bell Labs создавались процессоры с “прошитой” нечеткой логикой обработки информа-ции.
В начале 90-х компания Adaptive Logic из США выпустила кристалл, сделанный по аналогово-цифровой технологии (рис. 2). Он позволит сократить сроки конструирования многих встроен-ных систем управления реального времени, заменив собой тради-ционные схемы нечетких микроконтроллеров. Аппаратный про-цессор нечеткой логики второго поколения принимает аналоговые сигналы, переводит их в нечеткий формат, затем, применяя соот-ветствующие правила, преобразует результаты в формат обычной логики и далее – в аналоговый сигнал.
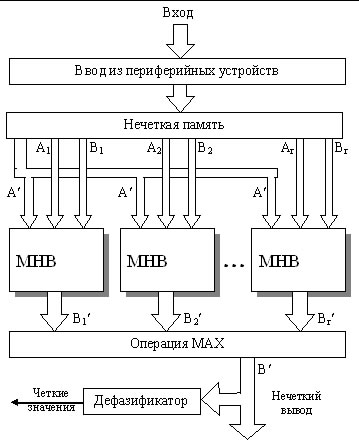
Рис. 2
Все это осуществляется без внешних запоминающих уст-ройств, преобразователей и какого бы ни было программного обеспечения нечеткой логики. Этот микропроцессор относительно прост по сравнению с громоздкими программными обеспечения-ми. Но так как его основу составляет комбинированный цифровой/ аналоговый кристалл, он функционирует на очень высоких скоростях ( частота отсчетов входного сигнала – 10 кГц, а скорость расчета – 500 тыс. правил/с), что во многих случаях приводит к лучшим результатам в системах управления по сравнению с более сложными, но медлительными программами.
В Европе и США ведутся интенсивные работы по интегра-ции fuzzy команд в ассемблеры промышленных контроллеров встроенных устройств (чипы Motorola 68HC11. 12. 21). Такие ап-паратные средства позволяют в несколько раз увеличить скорость выполнения приложений и компактность кода по сравнению с реализацией на обычном ядре. Кроме того, разрабатываются раз-личные варианты fuzzy- сопроцессоров, которые контактируют с центральный процессор через общую шину данных, концентриру-ют свои усилия на размывании/ уплотнении информации и опти-мизации использования правил (продукты Siemens Nixdorf).
Идеи нечеткой логики не являются панацеей и не смогут совершить переворот в компьютерном мире. Нечеткая логика не решит тех задач, которые не решаются на основе логики двоичной, но во многих случаях она удобнее, производительнее и дешевле. Разработанные на ее основе специализированные аппаратные ре-шения (fuzzy-вычислители) позволят получить реальные преиму-щества в быстродействии. Если каскадировать fuzzy-вычислители, мы получим один из вариантов нейропроцессора или нейронной сети. Во многих случаях эти понятия просто объединяют, называя общим термином «neuro-fuzzy logic».
В настоящее время перспективой использовать процессо-ры, основанные на нечеткой логике всерьез заитересовались воен-ные. Известно, что NASA рассматривает возможность применения (если еще не применяет) нечеткие системы для управления про-цессами стыковки космических аппаратов.
6.9. Сигнальные процессоры
В ответ на возросшие запросы потребителей фирма Motorola разработала новую архитектуру микросхемы, ориентиро-ванную как на выполнение сложных алгоритмов цифровой обра-ботки сигналов, так и на решение задач управления. Семейство микросхем DSP568xx построено на базе ядра 16-разрядного процессора DSP56800 с фиксированной точкой. Это ядро предна-значено для эффективного решения задач управления и цифровой обработки сигналов. Реализованный в нем набор команд обеспе-чивает цифровую обработку сигналов с эффективностью лучших DSP общего назначения и отвечает требованиям простоты созда-ния компактных программ управления.
Ядро DSP56800 является программируемым 16-разрядным КМОП процессором, предназначенным для выполнения цифровой обработки сигналов в реальном масштабе времени и решения вы-числительных задач. Ядро DSP56800 (рис. 3) состоит из четырех функциональных устройств: управления программой, генерации адресов, арифметико-логической обработки данных, обработки битов. Для увеличения производительности операции в устройст-вах выполняются параллельно. Каждое из устройств имеет свой набор регистров и логику управления и организовано таким обра-зом, что может функционировать независимо и одновременно с тремя другими. Внутренние шины адресов и данных связывают между собой память, функциональные и периферийные устройст-ва (регистры периферийных устройств расположены в области па-мяти). Таким образом, ядро реализует одновременное выполнение нескольких действий: устройство управления выбирает первую команду, устройство генерации адресов формирует до двух адре-сов второй команды, а АЛУ выполняет умножение третьей коман-ды. Есть альтернативная возможность: в третьей команде опера-цию может выполнять не АЛУ, а устройство обработки битов. Конвейерная архитектура позволяет реализовать параллельную работу устройств, входящих в состав микросхемы, и существенно сократить время выполнения программы.
Конвейерная архитектура ядра DSP56800 оптимизирована для обеспечения эффективности цифровой обработки сигналов, компактности программ управления и обработки сигналов, и удоб-ства программирования. Ниже приведены некоторые характери-стики сигнального процессора:
• производительность 40 MIPS при тактовой частоте 80 МГц и напряжении питания 2.7…3.6 В,
• наличие набора команд совмещенной обработки, имеющих режимы адресации, характерные для программ цифро-вой обработки сигналов,

Рис. 3
• однотактный параллельный 16х16 умножитель-сумматор,
167
• два 36-разрядных аккумулятора, включая биты расши-рения,
• однотактное 16-разрядное устройство циклического сдви-га,
• аппаратная реализация команд DO и REP,
• три внутренние 16-разрядные шины данных и три 16-разрядные шины адреса,
• одна 16-разрядная шина внешнего интерфейса,
• набор команд управления и цифровой обработки,
• режимы адресации такие же, как в сигнальных процессо-рах, и команды, снижающие объем программы,
• эффективный компилятор языка С и поддержка локаль-ных переменных,
• стек подпрограмм и прерываний, не имеющий ограниче-ния по глубине.
Для любого высокопроизводительного вычислителя, на-пример цифрового сигнального процессора, критичным является процесс ввода/вывода данных с большой скоростью, т. к. при этом замедляется обработка данных. Снижения производительности можно избежать путем использования гибкого набора команд со-вмещенной с выполнением вычислительных операций передачи данных. Реализованы два типа операций совмещенной передачи - одинарная совмещенная передача и сдвоенное совмещенное чте-ние. Оба типа операций существенно повышают скорость цифро-вой обработки сигналов и численных расчетов. Все команды DSP56800 с совмещенной передачей выполняются за один ко-мандный цикл и занимают одно слово в памяти программ.
Однократная совмещенная передача позволяет выполнить арифметическое действие и одну передачу данных (чтение или за-пись) за один командный цикл. Например, можно одной командой выполнить сложение двух чисел и одновременно данные из реги-стра АЛУ записать в память. Одновременно с этим в устройстве вычисления адресов производятся соответствующие вычисления.
Команда типа двойного совмещенного чтения допускает выполнение арифметической операции и чтения двух величин из Х-памяти данных в одной команде за один командный цикл. На-пример, можно в одной команде выполнить умножение двух чисел, просуммировать с третьим, округлить результат и одно-временно выполнить пересылку двух чисел из Х-памяти данных в два регистра АЛУ.
Обычные микроконтроллеры, как правило, имеют объем встроенной в микросхему памяти, достаточный для выполнения сложных алгоритмов управления без использования дополнитель-ной внешней памяти. Многие микросхемы DSP содержат встроен-ную память небольшого объема и, как правило, им требуется внешняя память для хранения программы. Микросхемы же семей-ства DSP56F8хх имеют встроенную память большого объема. Гар-вардская архитектура DSP обеспечивает наличие двух независи-мых областей памяти - данных и программ. Для хранения в микро-схеме данных и программ используется встроенная оперативная память и флэш-память.
Объём памяти каждого типа для микросхем семейства DSP56F8хх приведен в табл. 5. Как память программ, так и память данных могут быть расширены путем подключения внешней па-мяти. Микросхемы DSP56F803, DSP56F805, DSP56F807 допуска-ют расширение объема внешней памяти до 64 К слов.
Таблица 5

Широкий набор периферийных устройств обычно являлся основной характеристикой микроконтроллеров, встраиваемых в устройства общего назначения. С другой стороны, обычные DSP были ориентированы на численную обработку сигналов и не со-держали полного набора встроенных периферийных устройств, необходимых для решения задач управления. Использование внешних периферийных устройств приводит к увеличению числа
микросхем, усложнению платы и существенному возрастанию стоимости изделия.
Микросхемы семейств DSP56F8хх (рис. 4, табл. 6) имеют широкий набор встроенных периферийных устройств, пригодных для использования в системах управления всех типов

Рис. 4

. Этот набор встроенных устройств существенно снижает цену системы по сравнению с реализацией устройств управления на основе традиционных DSP. Более того, так как встроенные уст-ройства имеют заранее определенный интерфейс с ядром DSP (в отличие от внешних периферийных устройств), то упрощаются разработка системы, программирование и управление периферий-ными устройствами. Таким образом, время разработки программ сокращается. Микросхема DSP56F805 содержит следующие пери-ферийные блоки:
• два шестиканальных ШИМ-генератора (PWMA & PWMB) с привязкой импульсов к центру или краю временного интервала, программированием длительности "мертвого времени" и защитой в случае возникновения аварийных режимов работы; каждый ге-нератор снабжен тремя сенсорами тока и четырьмя входами ава-рийного отключения,
• два 12-разрядных АЦП с одновременной выборкой, снаб-женные входными четырехканальными мультиплексорами,
• два квадратурных (синусно-косинусных) декодера (Quad Dec0 & Quad Dec1), каждый с четырьмя входами (или два дополнительных четырехканальных таймера A&B),
• два четырехканальных таймера общего применения с ше-стью входами: таймер C с двумя входами и таймер D с четырьмя входами,
• контроллер CAN интерфейса A/B с двухвыводными пор-тами приемопередатчиков,
• два двухпроводных последовательных коммуникацион-ных интерфейса (SCI0 & SCI1) или 4 дополнительных линии GPIO,
• последовательный интерфейс периферии (SPI) с настраи-ваемым четырехпроводным портом или четыре дополнительные линии GPIO,
• сторожевой таймер контроля функционирования процес-сора,
• два программируемых входа внешних прерываний,
• четырнадцать программируемых и восемнадцать мульти-плексированных универсальных портов ввода/вывода (GPIO),
• вход принудительного сброса процессора,
• порт JTAG/OnCE™ (встроенного эмулятора) для отладки, не зависящей от тактовой частоты процессора,
• программируемый генератор с ФАПЧ для формирования тактовой частоты ядра DSP.
В системах управления, как правило, интенсивно исполь-зуются прерывания от внешних устройств и внутренних перифе-рийных модулей. Обычно микроконтроллеры поддерживают не-сколько типов внутренних и внешних прерываний и обеспечивают много вариантов маскирования и установки приоритетов.
Обычные DSP обрабатывают только небольшой набор пре-рываний, которые напрямую взаимодействуют с его ядром. В от-личие от них, кристалл DSP56F80х поддерживает большое число прерываний. Хотя число адресуемых прерываний ядра DSP56F8хх мало в сравнении с общим число источников прерываний, много-уровневая встроенная схема мультиплексирования обеспечивает полную и гибкую поддержку 64 источников прерываний, каждый
из которых может маскироваться и имеет программно устанав-ливаемый приоритет.
Разработка систем на базе микросхем семейства DSP56800 отличается простотой. Внешняя шина обеспечивает выполнение и отладку прикладных программ, размещенных во внешней памяти. Допускается хранение программ и данных во внешней памяти. Чтобы обеспечить функционирование внешней памяти с различ-ным быстродействием программируемые временные задержки для памяти программ и памяти данных могут устанавливаться раз-дельно.
Набор команд общего назначения, который используется в микропроцессорах с развитыми режимами адресации и командами обработки битов, дает разработчику возможность просто освоить программирование. Сложности, характерные для DSP с предшест-вующими архитектурами, не доставят ему беспокойства. Про-граммный стек обеспечивает неограниченное число прерываний и вложений подпрограмм, а также поддержку передачи параметров и локальных переменных. Опытный программист найдет широкий набор команд арифметических операций и различные одинарные и двойные обращения к памяти, выполняющиеся совместно с ариф-метическими операциями. Эффективная работа трансляторов для микросхем с архитектурой DSP56800 обеспечивается использова-нием в микросхемах команд общего назначения.
Порт отладки JTAG позволяет отлаживать микросхему в составе законченной системы пользователя. Через порт можно за-дать точки останова программы, проверить и изменить содержи-мое регистров и ячеек памяти, выполнить другие действия по от-ладке системы.
Motorola предлагает полный набор программных и аппарат-ных средств быстрой разработки и отладки систем, реализованных на кристаллах семейства DSP568хх. Средства разработки включа-ют:
• оценочные платы для каждой модификации микросхемы,
• интегрированную среду отладки "Metrowerks Code Warrior" со встроенным кросc-компилятором языка С.
Программная среда разработки предоставляет программи-сту гибкое модульное окружение, обеспечивая полное использова
ние возможностей микросхем. Среда допускает различные кон-фигурации памяти данных и позволяет создавать перемещаемый код, выполнять символьную отладку, гибко компоновать объект-ные файлы. Реализованы средства создания архива библиотек при-кладных программ.
Motorola разработала новый комплект для разработки встроенного программного обеспечения (Embedded Software Development Kit, SDK), дополняющий существующую среду раз-работки для DSP568xx. Он формирует программную инфраструк-туру, обеспечивающую разработку высокоэффективных программ, полностью переносимых и допускающих повторное использова-ние не только в процессорах семейства DSP568хх, но в будущем и в процессорах с другой архитектурой, поддерживаемой SDK. Этот программный продукт, выпускаемый для цифровых сигнальных процессоров фирмы Motorola, предназначен для ускорения разра-ботки и более быстрого выхода изделий на рынок.
Стандартные микроконтроллеры успешно применяются в устройствах управления общего назначения. Однако невысокая производительность не позволяет использовать их в устройствах с повышенными параметрами. Эта ниша заполняется микросхемами семейства DSP568хх, имеющими производительность DSP и снабженными набором периферийных устройств, которые тради-ционно используют разработчики систем управления.
Архитектура ядра DSP568хх обеспечивает эффективную цифровую обработку данных и решение задач управления. Такие характеристики этой архитектуры, как высокая производитель-ность и набор команд общего назначения, обеспечивают ей лиди-рующие позиции в тех областях цифровой обработки сигналов, в которых требуется низкая стоимость и малое энергопотребление. Компактность программ и высокая эффективность компилятора позволяет также снизить стоимость системы за счет уменьшения требуемого объема встроенной памяти.
Микросхемы семейства DSP568хх предназначены для при-менения в недорогих устройствах. Эти микросхемы ориентирова-ны на применение в бытовой технике, для которой необходима низкая стоимость и не требуются высокие параметры. К таким из-делиям относятся:
• специализированные и многоцелевые контроллеры,
• проводные и беспроводные модемы,
• системы беспроводной передачи цифровых сообщений,
• цифровые телефонные автоответчики,
• устройства управления серводвигателями и электродвига-телями переменного тока,
• цифровые камеры.
Микросхемы этого семейства имеют производительность специализированных DSP. Благодаря наличию набора встроенных периферийных устройств эти микросхемы отвечают требованиям систем управления. Встроенные блоки памяти и периферийные устройства могут существенно снизить стоимость системы, пото-му что в этом случае уменьшается число внешних компонентов.